What is Feed Forward? Understanding the Foundation of Neural Networks
- Published on
- Arnab Mondal--12 min read
Overview
- What is Feed Forward?
- How Feed Forward Works
- Mathematical Foundation
- Real-World Applications
- Implementation Example
- Conclusion
Feed forward is the cornerstone mechanism that powers modern neural networks. As someone who has worked extensively with machine learning models, I've found that understanding feed forward is crucial for grasping how neural networks process information and make predictions. In this article, I'll break down what feed forward means, how it works, and why it's essential for building effective AI systems.
What is Feed Forward?
Feed forward, also known as forward propagation, is the process by which data flows through a neural network in one direction—from the input layer through hidden layers to the output layer. Unlike feedback systems, feed forward networks don't have cycles or loops; information moves only forward, making them straightforward to understand and implement.
The term "feed forward" describes the unidirectional flow of information where each layer receives input from the previous layer, processes it, and passes the result to the next layer. This process continues until the final output is generated.
Real-World Analogy: Assembly Line Manufacturing
Think of a feed forward neural network like an automotive assembly line. Raw materials (input data) enter at the beginning, and each station (layer) performs specific operations:
- Station 1 (Input Layer): Receives raw materials like steel, plastic, and electronics
- Station 2 (Hidden Layer 1): Shapes and molds the materials into basic components
- Station 3 (Hidden Layer 2): Assembles components into larger parts
- Station 4 (Output Layer): Produces the final car
Just like in an assembly line, materials flow in one direction only—you can't send a partially assembled car back to an earlier station. Each station has specialized workers (neurons) who know exactly what to do with the materials they receive, and they pass their work forward to the next station.
How Feed Forward Works
Let me walk you through the step-by-step process of how feed forward operates in a neural network:
Step 1: Input Processing
The journey begins when raw data enters the input layer. Each input neuron receives a value (which could be a pixel intensity, word embedding, or any numerical feature) and passes it forward to the first hidden layer.
Analogy: Imagine you're at a restaurant ordering system. The input layer is like the menu where you select your preferences (appetizer, main course, dessert). Each choice is a specific input value that gets passed to the kitchen.
Step 2: Weighted Sum Calculation
Each neuron in the hidden layer calculates a weighted sum of all inputs from the previous layer. This is where the "learning" happens—the weights are the parameters that the network adjusts during training.
Analogy: Continuing with the restaurant example, this is like the head chef deciding how to combine ingredients. Each ingredient (input) has a different importance (weight) in the final dish. The chef might say "I'll use 30% of the customer's preference for spicy food, but reduce it by 70% if they ordered a mild dish, and add 50% of their preference for fresh ingredients."
Step 3: Activation Function Application
The weighted sum is then passed through an activation function, which introduces non-linearity to the network. This is crucial because without activation functions, the entire network would be equivalent to a single linear transformation.
Analogy: This is like the quality control checkpoint in our restaurant. The chef has prepared the dish (weighted sum), but now it goes through a taste test (activation function). If the dish is good (positive value), it passes through; if it's terrible (negative value), it gets rejected or modified. Different activation functions are like different quality standards—some are strict (ReLU rejects anything negative), while others are more forgiving (Sigmoid accepts everything but with different intensities).
Step 4: Forward Propagation Through Layers
This process repeats for each subsequent layer until the final output is produced. Each layer transforms the data in some way, gradually building up more complex representations.
Analogy: In our restaurant, this is like having multiple kitchen stations. The appetizer station (first hidden layer) prepares the starter and passes it to the main course station (second hidden layer), which then passes the complete meal to the plating station (output layer). Each station adds its expertise and transforms the food, building up to the final presentation that reaches the customer.
Feed Forward Network Architecture
Here's a visual representation of how feed forward works in a typical neural network:
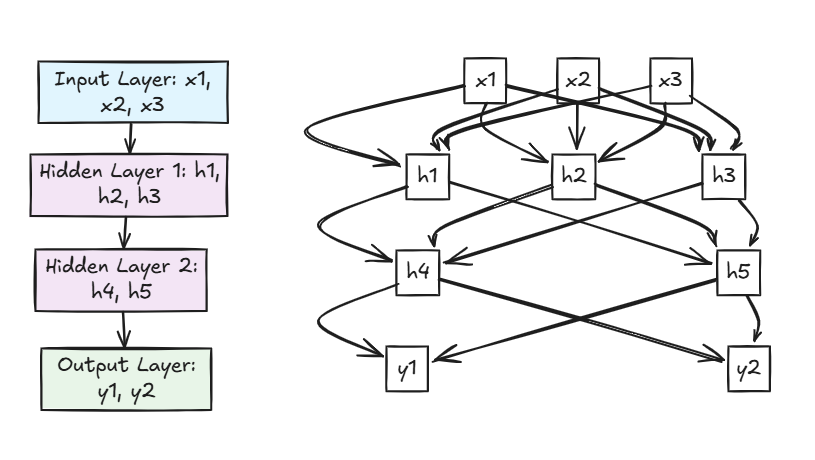
Mathematical Foundation
The mathematical representation of feed forward is elegant and powerful. For a network with L layers, the forward propagation can be expressed as:
For layer l:
Where:
z^(l)is the weighted sum (pre-activation) for layer lW^(l)is the weight matrix for layer la^(l-1)is the activation from the previous layerb^(l)is the bias vector for layer lg()is the activation function
Key Characteristics of Feed Forward Networks
1. Unidirectional Flow
Information flows only from input to output, never backward during inference. This makes feed forward networks deterministic and predictable.
Analogy: Like a one-way street in a city. Traffic (data) can only move in one direction—from point A to point B. You can't turn around and go back to an earlier intersection (layer) once you've passed it.
2. No Memory
Feed forward networks don't retain information from previous inputs. Each forward pass is independent, making them stateless systems.
Analogy: Think of a vending machine. Each time you make a purchase, the machine processes your current selection independently. It doesn't remember what you bought yesterday or what the previous customer ordered. Each transaction is completely separate.
3. Layered Architecture
The network is organized into distinct layers, each performing specific transformations on the data.
Analogy: Like a factory production line with specialized departments. The raw materials department (input layer) passes materials to the assembly department (hidden layers), which then sends the product to the packaging department (output layer). Each department has a specific role and expertise.
4. Parallel Processing
Within each layer, all neurons can process their inputs simultaneously, making feed forward networks highly parallelizable.
Analogy: Imagine a team of chefs working simultaneously in a restaurant kitchen. While one chef prepares the pasta, another is grilling the meat, and a third is making the salad—all at the same time. This parallel processing makes the kitchen much more efficient than having one chef do everything sequentially.
Common Activation Functions in Feed Forward
The choice of activation function significantly impacts the network's performance. Here are the most commonly used ones:
ReLU (Rectified Linear Unit)
Advantages: Simple, computationally efficient, helps with vanishing gradient problem Use case: Most hidden layers in modern networks
Analogy: Like a strict bouncer at a club. If you're positive (good vibes), you get in at full strength. If you're negative (bad vibes), you're completely rejected—no entry at all.
Sigmoid
Advantages: Smooth, bounded output (0 to 1) Use case: Binary classification output layers
Analogy: Like a gentle volume knob on a stereo. No matter how loud or quiet the input signal is, the output is always between 0 and 1 (silent to maximum volume). It's smooth and gradual, never abrupt.
Tanh (Hyperbolic Tangent)
Advantages: Zero-centered, bounded output (-1 to 1) Use case: Hidden layers, especially in RNNs
Analogy: Like a balanced scale that can tip either way. It's centered at zero (neutral), but can swing to positive or negative values, always staying within reasonable bounds (-1 to 1). Perfect for situations where you need both positive and negative outputs.
Feed Forward vs. Other Network Types
Understanding how feed forward differs from other architectures helps clarify its role:
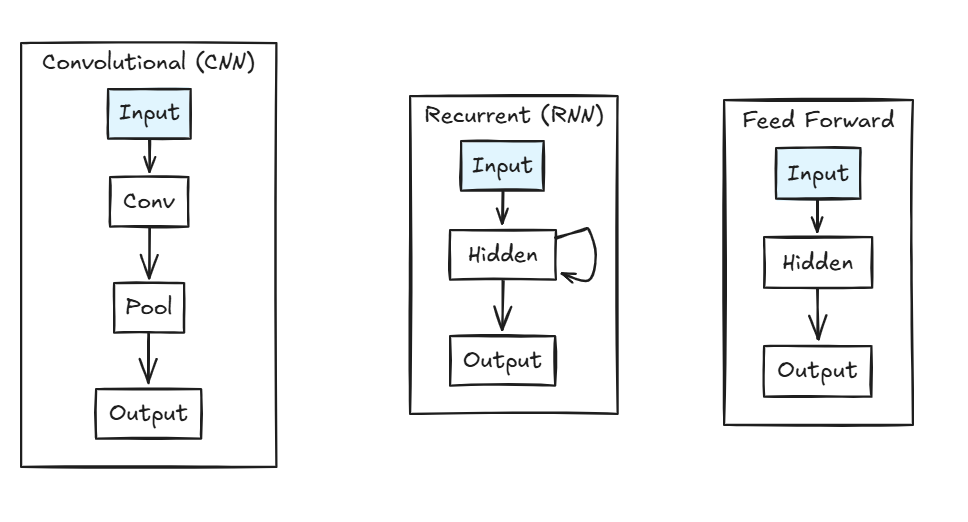
Feed Forward: Simple, stateless, great for pattern recognition Recurrent: Has memory, processes sequences, used for time series Convolutional: Specialized for spatial data like images
Real-World Applications
Feed forward networks power many applications we use daily:
1. Image Classification
- Example: Identifying objects in photos
- Architecture: Input (pixels) → Hidden layers → Output (class probabilities)
2. Natural Language Processing
- Example: Sentiment analysis, text classification
- Architecture: Input (word embeddings) → Hidden layers → Output (sentiment score)
3. Recommendation Systems
- Example: Netflix movie recommendations
- Architecture: Input (user features) → Hidden layers → Output (rating predictions)
4. Financial Modeling
- Example: Credit scoring, fraud detection
- Architecture: Input (financial features) → Hidden layers → Output (risk score)
Advantages and Limitations
Advantages
- Simplicity: Easy to understand and implement
- Speed: Fast inference once trained
- Parallelization: Can process multiple inputs simultaneously
- Universal Approximation: Can approximate any continuous function given enough neurons
Analogy: Feed forward networks are like reliable postal services. They're straightforward (you put mail in, it gets delivered), fast (once the route is established), can handle multiple packages simultaneously (parallel processing), and can deliver to any address (universal approximation). However, they can't remember previous deliveries or adapt their route based on past experiences.
Limitations
- No Memory: Cannot handle sequential dependencies
- Fixed Input Size: Requires inputs of predetermined dimensions
- Limited Context: Cannot consider previous inputs when processing current input
Analogy: These limitations are like a restaurant that doesn't remember customers. Each meal is prepared from scratch without considering what the customer ordered last time, the menu has a fixed number of items (fixed input size), and the chef can't adapt the current dish based on what was served in previous courses.
Implementation Example
Here's a simple feed forward network implementation in Python:
Conclusion
Feed forward is the fundamental mechanism that enables neural networks to process information and make predictions. By understanding how data flows unidirectionally through layers, how weights and biases transform inputs, and how activation functions introduce non-linearity, you gain insight into the core principles of modern AI systems.
While feed forward networks have limitations—particularly their inability to handle sequential data or maintain memory—they remain the foundation upon which more complex architectures like CNNs and RNNs are built. Whether you're building image classifiers, recommendation systems, or financial models, the principles of feed forward propagation are essential knowledge for any machine learning practitioner.
The beauty of feed forward lies in its simplicity: take inputs, transform them through learned parameters, and produce outputs. Yet this simple concept, when scaled and optimized, has revolutionized how we approach pattern recognition and prediction tasks across countless domains.
Ready to dive deeper? Consider exploring backpropagation (the learning mechanism that trains feed forward networks) or experimenting with different activation functions to see how they affect network performance.
Available for hire - If you're looking for a skilled full-stack developer with AI integration experience, feel free to reach out at hire@codewarnab.in